- API
- Scraping
How I saw too much information coming back from a company’s backend
Uncover the story of a seemingly ordinary project that evolved into an exploration of API security and backend vulnerabilities, sparked by an initial scripting task aimed at collecting product data from various web sources.
Written By
Tomer GreenwaldPublished Date
Aug 28 2022Read Time
13 minutes
In this Article
A few years ago, I was working on a project where we needed to get a bunch of data about products from various sources around the web. As often happens, what started as a small scripting task that I could just knock out in the background (in my “free time”) turned into an interesting adventure of API discovery and exploration, with a layer of security insights for good measure.
It all started from how to actually fetch the data.
Sometimes the data itself is directly available as structured databases. That’s where you can directly interact with a SQL or NoSQL database to extract relevant information. The great thing about these kinds of data sources is that they can help you make use of their data just with their existing internal structuring. A quick look at their table structure, identifiers, and the way they link data points can already be a great jump start to building a domain-specific knowledge graph. And of course you can then easily retrieve any data point you want, or all data points, by simply making the right queries.
Other times an API is available to retrieve the data directly. From the perspective of my needs, that’s a data API. These data APIs may be monetized by their owners with a paywall or may be free to use, but either way, they’re inevitably well-structured and well-documented APIs clearly meant for external users to interact with. Usually, you will get some tutorials to help you understand how to make sense of them and work with them, guides about the internal data schemes, and sometimes also instructions for working with them in production-scale environments (thresholds, order of calls, batching, …).
But in (desperate) times, all you have is the presentation of that data as HTML on web pages. In other words, you see a website showcasing the data you want to retrieve, but it’s grouped in categories, perhaps shown in cards, and searchable using a search box at the top of the website. You see that the data is all there, but it's not directly available to you, since it's rendered in HTML and encapsulated in DIVs and tables – in other words, data and presentation are combined to make a human-oriented presentation rather than a machine-oriented data source. Naturally, when you see this, you think: let’s just scrape the page by retrieving the HTML, mapping the various data structures we want to work with, and then extracting the data with some scripting language, an XML parser, or both. (BTW, my preference is extracting the data with regex vs using XPath).
But these days the mixing of data and HTML to create the presentation layer is likely done in the browser, within a single-page app, rather than server-side. Which means the browser likely fetched the data before wrapping it up in presentation elements. And if the browser can get data that way, you and I can do the same: skip the middle steps and just extract the data directly from the same HTTP calls the web page is making. I call that scraping the API because the developers behind the web site were effectively exposing an API, knowingly or not, but one geared towards HTML presentation, so to get at the data requires mapping this presentation API back into a data structure and using it as an effective data API.
How do you scrape an API? You start by exploring it
We start by deciding what data we want to scrape from the website. In our case, we wanted to build a product catalog, therefore the end goal was to get detailed information for all available items. For that, we needed to discover, i.e. list, all available items. The specific site structure only allowed listing items within a category, so we needed a way to discover (list) categories as well. It became clear that I would need to discover much if not all the API surface for this presentation API: its methods, data types, structures, allowed values, and whatever matching identifiers were used to link calls (e.g., an identifier retrieved when calling one method can be used when calling another method).
Usually, when I want to understand an undocumented API and I have access to a working example of that API being used, I start by inspecting how the example calls and consumes that API. In our case we had a browser application communicating with the API server using HTTP/REST, so a really easy tool for inspecting the traffic is just the built-in Chrome Developer Tools - Network tab:
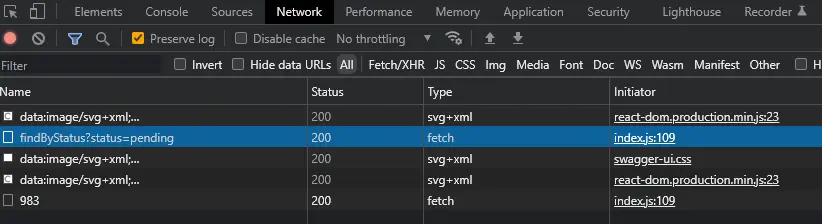
Another tool I highly recommend is Postman Interceptor. It has a much cleaner user interface and any reader already using Postman (is there anyone not using it?) should feel right at home using the Interceptor.
When inspecting all communication between the browser and the backend, we need to differentiate between requests made specifically to the API server and requests made to other parts of the backend for rendering the website. The API server calls will usually fall under the XHR category. Any calls there are a good tell-tale for an API we may be able to consume.
For each of the relevant pages and calls I wanted to map, I initiated multiple calls to the backend by entering different values in search boxes, selecting items in drop-down menus, and clicking items. With all these calls to the backend, I listed available API calls and their respective parameters. By piecing the puzzle pieces together, I figured out that there were several identifiers I needed to track, e.g. category_id and product_id. Calls often work as a hierarchy: the first call returns a list of identifiers, you then use those to make another call and get back more identifiers, and so on.
Here’s an example of three calls I needed to make in a specific order:
/list_categories returned categories with detailed info about the category. Critically, from that list I could retrieve category_id values to make the next call.
/list_products/{category_id} listed the products within a given category. From it, I could retrieve product_id values that allowed me, in turn, to make the next call.
/get_product/{product_id} returned a lot of data about the product – which was the end goal.
You can see that I’m effectively reverse-engineering the API spec:
paths:
/list_categories:
get:
summary: “List all categories”
/list_products/{category_id}:
get:
summary: “List all products in the given category”
/get_product/{product_id}:
get:
summary: “Return the product information for the given product”
With this home-brewed data API spec, we can start implementing the scraper.
Building a scraper
With all functions in hand, the basic scraping logic looked like this:
products = []
for category in list_categories():
for product in list_products(category):
products.append(get_product(product))
This worked at a small scale, to check that the logic made sense and I could scrape the data correctly. But to do it at full scale, with numerous calls to pick up all the data available, required dealing with the problems common to all scraping techniques: multi-threading, caching, data filtering, and related batching concerns.
Caching
The core scraping logic assumed we were dealing with a tree-like structure where there’s a single path between the root node and each leaf node (e.g. product). But as the code started making the API calls, and I started examining the retrieved IDs, I realized that the data structure we were looking at wasn’t a tree: a leaf node might be reachable from the root via multiple paths. The code would wastefully retrieve items multiple times unless we added a caching layer.
The first implementation for a caching layer was the simplest. The API used REST (well, roughly) over HTTP, so I figured we could cache calls by the HTTP path and request parameters.
To make sure all calls made were really necessary, I first created a proxy function that returned results from cache if they were in the cache (cache hits), and only made outbound API calls if they were not (cache misses). Once I switched all requests.get calls to use the proxy, I plugged the caching mechanism into that proxy.
Over time, we made the caching more sophisticated:
- We allowed the application to force a call even if it was already in the cache, to refresh items that might have gone stale.
- We allowed the application to “teach” the cache that some calls might look different but amount to the same result, e.g. by providing the cache with hints that some parameters were not part of the data semantics.
- We added some logic behind the cache to understand when an item was already processed on the back end so we could avoid making the HTTP call completely. For example, sometimes there were multiple types of calls that would retrieve information on the same item, so even though a certain type of call was not made and hence isn’t in the cache, we don’t need to make it because we already have the data about the item.
Parallelizing
When making 10K+ synchronous API calls to any server, you often start noticing that your process spends most of its time waiting for requests to complete. Because I knew most requests weren’t dependent on other requests to be completed, I could (and did) parallelize them to achieve much higher overall throughput.
Working around anti-scraping roadblocks
Sites usually don’t expect you to scrape them or their backend, but that doesn’t mean they don't implement basic anti-scraping mechanisms.
One of the basic ways which websites, API gateways, and WAFs use to verify who is making the request is the presence of a “normal” looking User-Agent field in the HTTP request. That’s because usually, when HTTP calls are generated using automated scripting or dev tools, they either contain an empty User-Agent or an SDK-specific User-Agent. On the other hand, web browsers specify their User-Agent in a format that looks like:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36
This identifies to the web server the exact type of browser it’s working with. To simulate a normal browser and avoid potential blocking on the server side, we can simply send this HTTP header ourselves to look like a standard Chrome browser (in this example).
Another check which web servers often make to ensure they’re getting requests from “normal” clients is by sending, and expecting back, certain cookies. Cookies are of course used by websites for functional reasons, such as preference tracking (site language), form tracking, and so on. But websites can also use cookies for sanity checks when API calls are made to their backend. A common example is a site creating and sending a unique “session” cookie the first time you visit any of its pages. The site then expects and validates this cookie when you call its API. If you see you’re being blocked because of such a mechanism, you’ll first need to figure out which cookies are being set by this site and returned in its API calls, and then send them with your automated scraping. To do this, you might simply copy them from your browser, or if needed you can automatically discover them by making the right initial HTTP call to the backend – that initial call that returns the session cookie the first time.
What I discovered
Once I had the API scraping automated, I turned to the data I was building up, and made some interesting discoveries.
First, I noticed that not all of the data returned in a response was actually needed for rendering the pages I was looking at. That was glaringly obvious when I saw that responses to describe individual products were several KBs long, but there wasn’t nearly enough data represented on the screen to consume that (excluding images, as they were retrieved separately anyway). In fact, the data looked like it was simply the unfiltered output of an internal system that the API server was fronting, sometimes even multiple systems, because I could see bits of schemas and identifiers that were quite different than the identifiers and schemas I had reverse-engineered from the presentation API.
This isn’t just a matter of the API being inefficient; it often poses a real security risk for the site and the business, as you could use and abuse these internal identifiers to:
- Identify which specific backend systems are being used. This knowledge can be combined with catalogs of known vulnerabilities (e.g. from the Cybersecurity and Infrastructure Security Agency) to exploit those systems, perhaps with specifically crafted malicious payloads.
- Identify new APIs – sources of data – that can then be probed directly. For example, you might see a fragment of data that suggests the existence of another API for shipping partners; perhaps that API relies on “security through obscurity” but can be queried directly to reveal preferred shipping rates and other confidential information?
- Identify new values that should not be exposed but are not in fact protected. For example, if product identifiers are sequential, then sending sequences of product IDs might reveal products that are not yet released and allow competitors to get a head start.
In some cases, I realized that information which might not be regarded as sensitive on its own became more concerning when collected in bulk. Think of item stock levels, used to present availability indicators in stores. Users can benefit from learning whether an item would be present when they go to the store to pick up their item, or how long it might take to get delivered to them. But when we accumulate many availability data points for a product over time, we can learn about its sales cycle, its replenishment frequency, and other telling metrics about the business.
Takeaways
While it’s intriguing to embark on such a “fishing expedition” and see what can be learned with a bit of scripting, I think the important lessons here are for the developers of backend systems, in particular ones that need to support front-end development.
It seems very natural for developers to repurpose internal APIs when the UI needs data, reusing previous investments rather than building new APIs from scratch. Reuse of what’s readily available is a pillar of software development, whether it’s building on existing open-source software or extending existing APIs. And it seems equally natural to assume that, since the same company is building the front end and the APIs behind it, that these APIs are private and therefore… protected?
But the true boundary of these APIs is, at best, the corporate network: once they are exposed to the public internet, as they must be if they’re to serve public web pages, anyone can discover and access them, just as I did, for good purposes or otherwise.
Such APIs are, in fact, public APIs. Their purpose might be private – so, e.g., they need not be managed carefully like APIs meant for external consumption and integration need to be – but their security model must be appropriate for a public API. A good way to think about them is as products, intended for external consumption, and even if the expected mode of consumption is via a browser, like any consumer product the “manufacturer” must consider unexpected usage.
A productized API benefits from several important elements. This has been described elsewhere at great length (just Google it), but here I want just to highlight a couple of important points.
Formalize the API specification – the resources, methods, request data and response data, and don’t forget the responses when errors happen. Just declaring the fields and types of data that can pass between systems will trigger a sanity check for the teams responsible for producing and consuming the API, which already helps catch problems.
Really think about the data being exposed, individually as well as in bulk. For example, consider an online retail site that sends real-time item availability to its web UI, even if that UI may only render a simplistic view (available or not) to the consumer. Wouldn’t it be better to send only the information the UI needs, perhaps an enum with a couple of options, and expand that only if and when the needs change?
Meanwhile, for anyone needing to discover data from web APIs, explicit or implicit – happy hunting!
In this Article
Like this article?
Sign up for newsletter updates
Resource Library
Read blogs by Otis, run self-paced labs that teach you how to use Otterize in your browser, or read mentions of Otterize in the media.
- Kubernetes
New year, new features
We have some exciting announcements for the new year! New features for both security and platform teams, usability improvements, performance improvements, and more! All of the features that have been introduced recently, in one digest.
- Kubernetes
First Person Platform E04 - Ian Evans on security as an enabler for financial institutions
The fourth episode of First Person Platform, a podcast: platform engineers and security practitioners nerd out with Ori Shoshan on access controls, Kubernetes, and platform engineering.